struct 模块
Python struct 模块详解 - C 结构体与 Python 字节序列之间的打包与解包
struct 模块
📝 概述
struct 模块用于在 Python 与 C 语言结构体之间进行二进制数据转换。你可以使用格式字符串描述数据布局,然后将 Python 值“打包”为 bytes,或将二进制数据“解包”为 Python 值。它广泛应用于二进制文件处理、网络协议编解码、嵌入式数据交互等场景。
🎯 学习目标
- 掌握 pack、unpack、calcsize 的基本用法
- 理解格式字符串中的类型码与对齐、字节序控制
- 学会处理字符串、整数、浮点与布尔等常见类型
- 能够读写自定义的二进制记录,并与文件或网络套接字配合
📋 前置知识
- bytes/bytearray 基础与文件 I/O
- 基本的整数、浮点与字符串编码(如 UTF-8)
🔍 详细内容
常用函数
- struct.pack(fmt, v1, v2, …):根据格式字符串 fmt 将值序列打包为 bytes
- struct.unpack(fmt, buffer):按 fmt 从 buffer(bytes/bytearray/memoryview)中解包为元组
- struct.calcsize(fmt):计算按 fmt 布局所占字节数(与对齐相关)
字节序与对齐(格式前缀)
- ’@’:原生对齐与原生字节序(依赖平台)
- ’=’:原生字节序,标准尺寸,无对齐
- ’<’:小端(little-endian)
- ’>’:大端(big-endian)
- ’!’:网络字节序(big-endian,与 ‘>’ 等价)
建议网络协议或跨平台文件格式统一使用 ‘<’ 或 ‘!’ 显式指定,避免平台相关差异。
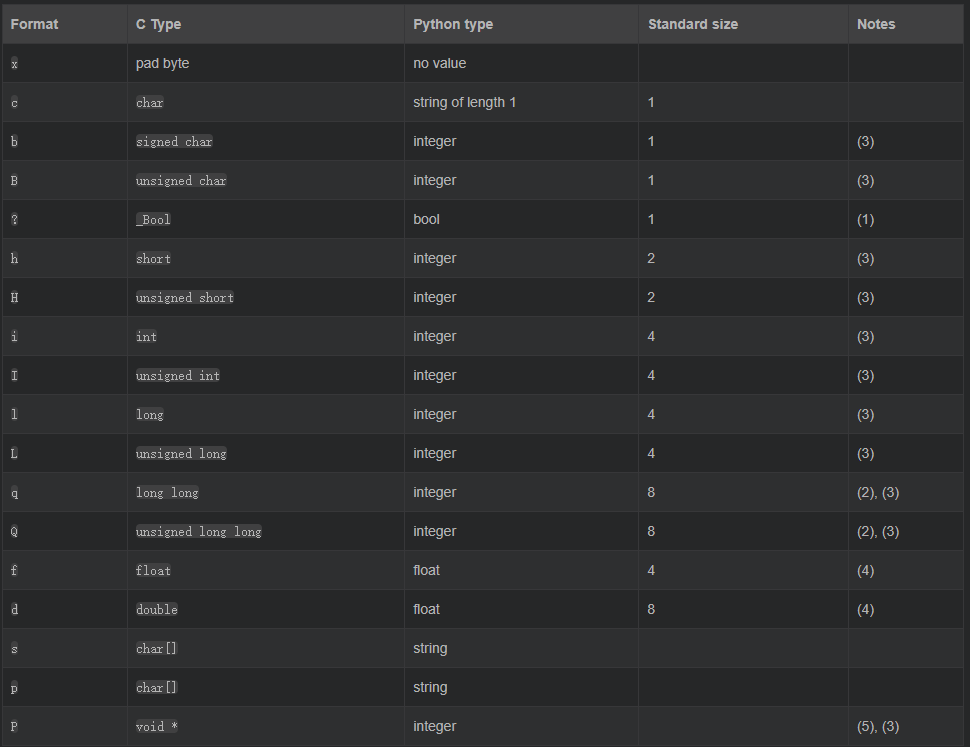
常见类型码(片段)
- ‘x’:填充字节(无值)
- ’?’:布尔(1 字节)
- ‘b’/’B’:有符号/无符号字节(1 字节)
- ‘h’/’H’:short(2 字节)
- ‘i’/’I’:int(4 字节)
- ‘q’/’Q’:long long(8 字节)
- ‘f’/’d’:float/double(4/8 字节)
- ’s’:字节串,形如 ‘4s’ 表示固定 4 字节
- ‘p’:以首字节为长度的 Pascal 风格字节串
数量前缀 n 作用于类型:如 ‘4s’、’2i’、’3h’ 等。
基本示例:打包与解包
# -*- coding: utf-8 -*-
import struct
# 定义格式:小端,4 字节 name,int age,6 字节 sex,7 字节 job
fmt = '<4si6s7s' # 使用显式小端,跨平台更稳定
name = b'lily'
age = 18
sex = b'female'
job = b'teacher'
# 打包为二进制
packed = struct.pack(fmt, name, age, sex, job)
print('packed bytes length =', len(packed))
# 解包回 Python 值
unpacked = struct.unpack(fmt, packed)
print(unpacked) # (b'lily', 18, b'female', b'teacher')
文件读写:二进制记录
# -*- coding: utf-8 -*-
import struct
fmt = '<4si6s7s'
record = struct.pack(fmt, b'lily', 18, b'female', b'teacher')
# 写入二进制文件
with open('test.bin', 'wb') as fp:
fp.write(record)
# 读取并解析
size = struct.calcsize(fmt)
with open('test.bin', 'rb') as fd:
data = fd.read(size)
print(struct.unpack(fmt, data))
关于字符串与编码
- ’s’/’p’ 对应的都是原始字节串,需要自行编码/解码:
- 文本 -> bytes:b’…’ 或 ‘文本’.encode(‘utf-8’)
- bytes -> 文本:b’…‘.decode(‘utf-8’)
解析网络协议报文示例
# -*- coding: utf-8 -*-
import struct
# 自定义报文头:魔数(2B) 版本(1B) 长度(2B) 标志(1B)
HEADER_FMT = '!H B H B' # 使用网络字节序(大端)
HEADER_SIZE = struct.calcsize(HEADER_FMT)
packet = b'\x12\x34' + b'\x01' + b'\x00\x10' + b'\x02' + b'PAYLOAD...'
magic, ver, length, flags = struct.unpack(HEADER_FMT, packet[:HEADER_SIZE])
print(hex(magic), ver, length, flags)
💡 实际应用
1. 读取顺序记录(流式处理大文件)
# -*- coding: utf-8 -*-
import struct
def iter_records(path, fmt):
size = struct.calcsize(fmt)
with open(path, 'rb') as f:
while True:
chunk = f.read(size)
if not chunk or len(chunk) < size:
break
yield struct.unpack(fmt, chunk)
for rec in iter_records('test.bin', '<4si6s7s'):
print(rec)
2. 与 socket 结合(接收固定头 + 变长体)
# -*- coding: utf-8 -*-
import struct, socket
HEADER_FMT = '!I' # 4 字节无符号整数,表示后续负载长度
HEADER_SIZE = struct.calcsize(HEADER_FMT)
s = socket.socket()
s.connect(('127.0.0.1', 9000))
# 读取固定长度函数
def recv_exact(sock, n):
buf = bytearray()
while len(buf) < n:
chunk = sock.recv(n - len(buf))
if not chunk:
raise ConnectionError('socket closed')
buf.extend(chunk)
return bytes(buf)
# 先读头,再按长度读体
header = recv_exact(s, HEADER_SIZE)
(payload_len,) = struct.unpack(HEADER_FMT, header)
payload = recv_exact(s, payload_len)
print('payload len =', len(payload))
⚠️ 注意事项
- 明确字节序与对齐:跨平台/跨语言建议用 ‘<’ 或 ‘!’,避免使用依赖平台的 ‘@’
- 字符串字段需自己编码/解码,固定长度不足时应按协议约定填充或截断
- 读取二进制时要检查长度是否足够,防止解包越界
- 浮点在不同平台/语言间可能有差异,协议中尽量使用整数表述(如定点数)或统一 double
🔗 相关内容
- binascii 模块 - 二进制与 ASCII 转换
- io 模块 - 文本与二进制 I/O
- bytes 内置类型 - 不可变字节序列
- bytearray 内置类型 - 可变字节序列
📚 扩展阅读
- 官方文档:struct — Interpret bytes as packed binary data
🏷️ 标签
二进制 打包 解包 数据格式 网络协议
原始文档(未改动保留)
以下为用户提供的原始内容,原样保留以便对照参考:
—–struct—–
软硬件环境
-
python3
-
struct
简介
struct是python(包括版本2和3)中的内建模块,它用来在c语言中的结构体与python中的字符串之间进行转换,数据一般来自文件或者网络。
常用方法
struct模块中的函数
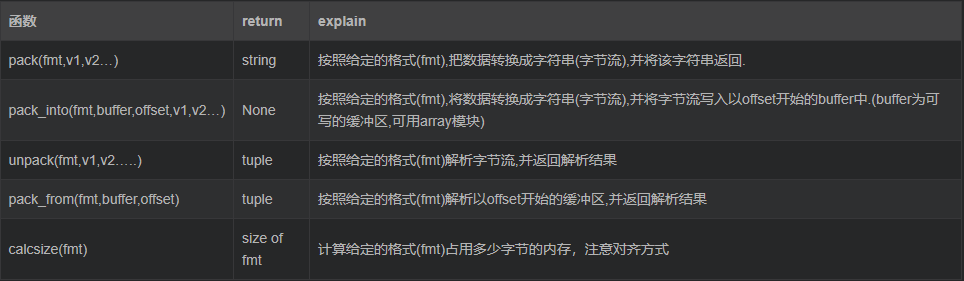
struct.pack(fmt,v1,v2,…)
返回的是一个字符串,是参数按照fmt数据格式组合而成。
struct.unpack(fmt,string)
按照给定数据格式解开(通常都是由struct.pack进行打包)数据,返回值是一个tuple
对齐方式
为了同c中的结构体交换数据,还要考虑c或c++编译器使用了字节对齐,通常是以4个字节为单位的32位系统,故而struct根据本地机器字节顺序转换.可以用格式中的第一个字符来改变对齐方式.定义如下
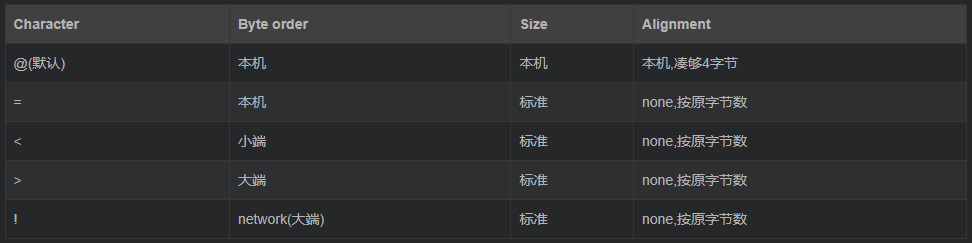
如果不懂大小端,见大小端参考网址.
实例
理论性的东西看起来都比较枯燥,来个实例代码就容易理解多了。本例来实现往一个2进制文件中按照某种特定格式写入数据,之后再将它读出。相信通过这个理例子,你就能基本掌握struct的使用。
# -*- coding: utf-8 -*-
__author__ = 'djstava'
'''
数据格式为姓名 年龄 性别 职业
lily 18 female teacher
'''
import os
import struct
fp = open('test.bin', 'wb')
# 按照上面的格式将数据写入文件中
# 这里如果string类型的话,在pack函数中就需要encode('utf-8')
name = b'lily'
age = 18
sex = b'female'
job = b'teacher'
# int类型占4个字节
fp.write(struct.pack('4si6s7s', name, age, sex, job))
fp.flush()
fp.close()
# 将文件中写入的数据按照格式读取出来
fd = open('test.bin', 'rb')
# 21 = 4 + 4 + 6 + 7
print(struct.unpack('4si6s7s', fd.read(21)))
fd.close()
运行上面的代码,可以看到读出的数据与写入的数据是完全一致的。
-
(b’lily’, 18, b’female’, b’teacher’)
-
-
Process finished with exit code 0
为了同c中的结构体交换数据,还要考虑有的c或c++编译器使用了字节对齐,通常是以4个字节为单位的32位系统,故而struct根据本地机器字节顺序转换.可以用格式中的第一个字符来改变对齐方式.定义如下:
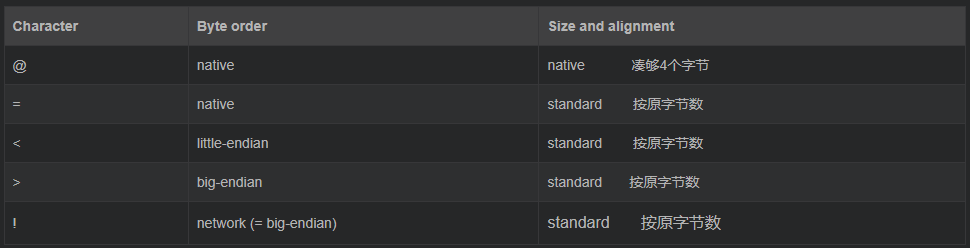
使用方法是放在fmt的第一个位置,就像’@5s6sif’
Python3 bytes 函数
描述
bytes 函数返回一个新的 bytes 对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列。它是 bytearray 的不可变版本。
语法
以下是 bytes 的语法:
class bytes([source[, encoding[, errors]]])
参数
-
如果 source 为整数,则返回一个长度为 source 的初始化数组;
-
如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
-
如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
-
如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
-
如果没有输入任何参数,默认就是初始化数组为0个元素。
返回值
返回一个新的 bytes 对象。
实例
以下展示了使用 bytes 的实例:
>>>a = bytes([1,2,3,4])
>>> a b'\x01\x02\x03\x04'
>>> type(a) <class 'bytes'>
>>>
>>> a = bytes('hello','ascii')
>>> >>> a b'hello'
>>> type(a) <class 'bytes'>
>>>
讨论与反馈
欢迎在下方留言讨论,分享你的学习心得或提出问题。评论基于GitHub Issues,需要GitHub账号。